Monday, July 17, 2017
Restart Phi after reboot the host machine
At host (q183),
1. Stop iptables: service iptables stop
2. Start nfs: service nfs start
3. Login to mic0,
add the following three lines to /etc/fstab
phi:/phi /phi nfs rsize=8192,wsize=8192,nolock,intr 0 0
phi:/opt /opt nfs rsize=8192,wsize=8192,nolock,intr 0 0
phi:/temp /temp nfs rsize=8192,wsize=8192,nolock,intr 0 0
then mount -a
Also add users in /etc/passwd and /etc/shadow
4. Repeat the same setup for mic1.
Directory structures: Users share /phi/$USER as their common home at mic0 and mic1 , and scratch files can be written under /temp, preferably /temp/$USER
/opt leads for /opt/intel and /opt/mpss, and /phi for packages compiled for Phi, stored under /phi/pkg.
Saturday, January 28, 2017
nwchem 6.6 compile log
ccuf1: Debian 7.7
Intel Compiler Version 17.0.1.132 Build 20161005
Python v2.7.3
. /pkg1/intel/compilers_and_libraries_2017/linux/bin/compilervars.sh intel64
echo $MKLROOT
/pkg1/intel/compilers_and_libraries_2017.1.132/linux/mkl
cd /pkg1
tar jxf /f01/source/chem/nwchem/Nwchem-6.6.revision27746-src.2015-10-20.tar.bz2
cd nwchem-6.6/src
# New start compilation setup
export NWCHEM_TOP=/pkg1/chem/nwchem-6.6
export FC=ifort
export CC=icc
export USE_MPI=y
export NWCHEM_TARGET=LINUX64
export USE_PYTHONCONFIG=y
export PYTHONVERSION=2.7
export PYTHONHOME=/usr
export BLASOPT="-L$MKLROOT/lib/intel64 -lmkl_intel_ilp64 -lmkl_core -lmkl_sequential \
-lpthread -lm"
export SCALAPACK="-L$MKLROOT/lib/intel64 -lmkl_scalapack_ilp64 -lmkl_intel_ilp64 -lmkl_core \ -lmkl_sequential -lmkl_blacs_intelmpi_ilp64 -lpthread -lm"
export NWCHEM_MODULES="all python"
ccuf0: Debian 4.0
Intel Compiler Version 14.0.2.144 Build 20140120
Python v2.4.4
. /opt/intel/composer_xe_2013_sp1.2.144/bin/compilervars.sh intel64
echo $MKLROOT
/opt/intel/composer_xe_2013_sp1.2.144/mkl
cd /temp
tar jxf /f01/source/chem/nwchem/Nwchem-6.6.revision27746-src.2015-10-20.tar.bz2
cd nwchem-6.6/src
# New start compilation setup
export NWCHEM_TOP=/temp/nwchem-6.6
export PATH="/pkg/x86_64/openmpi-1.6.5-i14/bin:$PATH"
export FC=ifort
export CC=icc
export USE_MPI=y
export NWCHEM_TARGET=LINUX64
export USE_PYTHONCONFIG=y
export PYTHONHOME=/usr
export PYTHONVERSION=2.4
export MPI_LOC=/pkg/x86_64/openmpi-1.6.5-i14
export MPI_LIB=/pkg/x86_64/openmpi-1.6.5-i14/lib
export MPI_INCLUDE=/pkg/x86_64/openmpi-1.6.5-i14/include
export LIBMPI="-lmpi_f90 -lmpi_f77 -lmpi -lpthread"
# export BLASOPT="-mkl -openmp"
export BLASOPT="-L$MKLROOT/lib/intel64 -lmkl_intel_ilp64 -lmkl_core -lmkl_sequential \
-lpthread -lm"
export SCALAPACK="-L$MKLROOT/lib/intel64 -lmkl_scalapack_ilp64 -lmkl_intel_ilp64 -lmkl_core \
-lmkl_sequential -lmkl_blacs_intelmpi_ilp64 -lpthread -lm"
export NWCHEM_MODULES="all python"
# Now start compilation
make nwchem_config >& nwchem.config.log &
make -j 8 >& make.log &
# Finally manually resolve undefined references to openmpi-ifort and python2.4
ifort -i8 -align -fpp -vec-report6 -fimf-arch-consistency=true -finline-limit=250 -O2 -g -fp-model source -Wl,--export-dynamic -L/temp/nwchem-6.6/lib/LINUX64 -L/temp/nwchem-6.6/src/tools/install/lib -L$MPI_LIB -o /temp/nwchem-6.6/bin/LINUX64/nwchem nwchem.o stubs.o -lnwctask -lccsd -lmcscf -lselci -lmp2 -lmoints -lstepper -ldriver -loptim -lnwdft -lgradients -lcphf -lesp -lddscf -ldangchang -lguess -lhessian -lvib -lnwcutil -lrimp2 -lproperty -lsolvation -lnwints -lprepar -lnwmd -lnwpw -lofpw -lpaw -lpspw -lband -lnwpwlib -lcafe -lspace -lanalyze -lqhop -lpfft -ldplot -lnwpython -ldrdy -lvscf -lqmmm -lqmd -letrans -lpspw -ltce -lbq -lmm -lcons -lperfm -ldntmc -lccca -lnwcutil -lga -larmci -lpeigs -lperfm -lcons -lbq -lnwcutil -lmpi_f90 -lmpi_f77 -lmpi -lpthread -lpython2.4 \
-L/opt/intel/composer_xe_2013_sp1.2.144/mkl/lib/intel64 -lmkl_intel_ilp64 -lmkl_core -lmkl_sequential
# See also /pkg/x86_64/chem/README.nwchem-6.6 at ccuf0 for running setup.
q183 Phi: CentOS 6.6 (Final)
Intel Compiler Version 17.0.1.132 Build 20161005
Python v2.6.6
. /opt/intel/compilers_and_libraries_2017/linux/bin/compilervars.sh intel64
echo $MKLROOT
/opt/intel/compilers_and_libraries_2017.1.132/linux/mkl
cd /phi
tar jxf /f01/source/chem/nwchem/Nwchem-6.6.revision27746-src.2015-10-20.tar.bz2
cd nwchem-6.6/src
# apply patches
# Compilation setup for Phi
export NWCHEM_TOP=/phi/nwchem-6.6
export USE_MPI=y
export NWCHEM_TARGET=LINUX64
export USE_PYTHONCONFIG=y
export PYTHONHOME=/usr
export PYTHONVERSION=2.6
export LD_LIBRARY_PATH=/usr/lib64/openmpi/lib/:$LD_LIBRARY_PATH
export PATH=/usr/lib64/openmpi/bin/:$PATH
export FC=ifort
export CC=icc
export USE_OPENMP=1
export USE_OFFLOAD=1
export BLASOPT="-mkl -qopenmp -lpthread -lm"
export SCALAPACK="-mkl -qopenmp -lmkl_scalapack_ilp64 -lmkl_blacs_intelmpi_ilp64 -lpthread -lm"
export BLASOPT="-mkl -openmp -lpthread -lm"
export NWCHEM_MODULES="all python"
Intel Compiler Version 17.0.1.132 Build 20161005
Python v2.7.3
. /pkg1/intel/compilers_and_libraries_2017/linux/bin/compilervars.sh intel64
echo $MKLROOT
/pkg1/intel/compilers_and_libraries_2017.1.132/linux/mkl
cd /pkg1
tar jxf /f01/source/chem/nwchem/Nwchem-6.6.revision27746-src.2015-10-20.tar.bz2
cd nwchem-6.6/src
# New start compilation setup
export NWCHEM_TOP=/pkg1/chem/nwchem-6.6
export FC=ifort
export CC=icc
export USE_MPI=y
export NWCHEM_TARGET=LINUX64
export USE_PYTHONCONFIG=y
export PYTHONVERSION=2.7
export PYTHONHOME=/usr
export BLASOPT="-L$MKLROOT/lib/intel64 -lmkl_intel_ilp64 -lmkl_core -lmkl_sequential \
-lpthread -lm"
export SCALAPACK="-L$MKLROOT/lib/intel64 -lmkl_scalapack_ilp64 -lmkl_intel_ilp64 -lmkl_core \ -lmkl_sequential -lmkl_blacs_intelmpi_ilp64 -lpthread -lm"
export NWCHEM_MODULES="all python"
ccuf0: Debian 4.0
Intel Compiler Version 14.0.2.144 Build 20140120
Python v2.4.4
. /opt/intel/composer_xe_2013_sp1.2.144/bin/compilervars.sh intel64
echo $MKLROOT
/opt/intel/composer_xe_2013_sp1.2.144/mkl
cd /temp
tar jxf /f01/source/chem/nwchem/Nwchem-6.6.revision27746-src.2015-10-20.tar.bz2
cd nwchem-6.6/src
# New start compilation setup
export NWCHEM_TOP=/temp/nwchem-6.6
export PATH="/pkg/x86_64/openmpi-1.6.5-i14/bin:$PATH"
export FC=ifort
export CC=icc
export USE_MPI=y
export NWCHEM_TARGET=LINUX64
export USE_PYTHONCONFIG=y
export PYTHONHOME=/usr
export PYTHONVERSION=2.4
export MPI_LOC=/pkg/x86_64/openmpi-1.6.5-i14
export MPI_LIB=/pkg/x86_64/openmpi-1.6.5-i14/lib
export MPI_INCLUDE=/pkg/x86_64/openmpi-1.6.5-i14/include
export LIBMPI="-lmpi_f90 -lmpi_f77 -lmpi -lpthread"
# export BLASOPT="-mkl -openmp"
export BLASOPT="-L$MKLROOT/lib/intel64 -lmkl_intel_ilp64 -lmkl_core -lmkl_sequential \
-lpthread -lm"
export SCALAPACK="-L$MKLROOT/lib/intel64 -lmkl_scalapack_ilp64 -lmkl_intel_ilp64 -lmkl_core \
-lmkl_sequential -lmkl_blacs_intelmpi_ilp64 -lpthread -lm"
export NWCHEM_MODULES="all python"
# Now start compilation
make nwchem_config >& nwchem.config.log &
make -j 8 >& make.log &
# Finally manually resolve undefined references to openmpi-ifort and python2.4
ifort -i8 -align -fpp -vec-report6 -fimf-arch-consistency=true -finline-limit=250 -O2 -g -fp-model source -Wl,--export-dynamic -L/temp/nwchem-6.6/lib/LINUX64 -L/temp/nwchem-6.6/src/tools/install/lib -L$MPI_LIB -o /temp/nwchem-6.6/bin/LINUX64/nwchem nwchem.o stubs.o -lnwctask -lccsd -lmcscf -lselci -lmp2 -lmoints -lstepper -ldriver -loptim -lnwdft -lgradients -lcphf -lesp -lddscf -ldangchang -lguess -lhessian -lvib -lnwcutil -lrimp2 -lproperty -lsolvation -lnwints -lprepar -lnwmd -lnwpw -lofpw -lpaw -lpspw -lband -lnwpwlib -lcafe -lspace -lanalyze -lqhop -lpfft -ldplot -lnwpython -ldrdy -lvscf -lqmmm -lqmd -letrans -lpspw -ltce -lbq -lmm -lcons -lperfm -ldntmc -lccca -lnwcutil -lga -larmci -lpeigs -lperfm -lcons -lbq -lnwcutil -lmpi_f90 -lmpi_f77 -lmpi -lpthread -lpython2.4 \
-L/opt/intel/composer_xe_2013_sp1.2.144/mkl/lib/intel64 -lmkl_intel_ilp64 -lmkl_core -lmkl_sequential
# See also /pkg/x86_64/chem/README.nwchem-6.6 at ccuf0 for running setup.
q183 Phi: CentOS 6.6 (Final)
Intel Compiler Version 17.0.1.132 Build 20161005
Python v2.6.6
. /opt/intel/compilers_and_libraries_2017/linux/bin/compilervars.sh intel64
echo $MKLROOT
/opt/intel/compilers_and_libraries_2017.1.132/linux/mkl
cd /phi
tar jxf /f01/source/chem/nwchem/Nwchem-6.6.revision27746-src.2015-10-20.tar.bz2
cd nwchem-6.6/src
# apply patches
# Compilation setup for Phi
export NWCHEM_TOP=/phi/nwchem-6.6
export USE_MPI=y
export NWCHEM_TARGET=LINUX64
export USE_PYTHONCONFIG=y
export PYTHONHOME=/usr
export PYTHONVERSION=2.6
export LD_LIBRARY_PATH=/usr/lib64/openmpi/lib/:$LD_LIBRARY_PATH
export PATH=/usr/lib64/openmpi/bin/:$PATH
export FC=ifort
export CC=icc
export USE_OPENMP=1
export USE_OFFLOAD=1
export BLASOPT="-mkl -qopenmp -lpthread -lm"
export SCALAPACK="-mkl -qopenmp -lmkl_scalapack_ilp64 -lmkl_blacs_intelmpi_ilp64 -lpthread -lm"
export BLASOPT="-mkl -openmp -lpthread -lm"
export NWCHEM_MODULES="all python"
smash 2.1.0 DFT @ Intel Phi
smash-2.1.0 DFT on q183 Phi: CentOS 6.6 (Final)
Python v2.6.6
. /opt/intel/compilers_and_libraries_2017/linux/bin/compilervars.sh intel64
. /opt/intel/impi/2017.1.132/bin64/mpivars.sh intel64
echo $MKLROOT
/opt/intel/compilers_and_libraries_2017.1.132/linux/mkl
echo $MIC_LD_LIBRARY_PATH
/opt/intel/compilers_and_libraries_2017.1.132/linux/mpi/mic/lib:/opt/intel/compilers_and_libraries_2017.1.132/linux/compiler/lib/mic:/opt/intel/compilers_and_libraries_2017.1.132/linux/ipp/lib/mic:/opt/intel/mic/coi/device-linux-release/lib:/opt/intel/mic/myo/lib:/opt/intel/compilers_and_libraries_2017.1.132/linux/compiler/lib/intel64_lin_mic:/opt/intel/compilers_and_libraries_2017.1.132/linux/mkl/lib/intel64_lin_mic:/opt/intel/compilers_and_libraries_2017.1.132/linux/tbb/lib/mic
Compile on host with for the intel64 architecture
cd /phi/pkg/smash-2.1.0
cp Makefile Makefile.mpiifort
Edit Makefile.mpiifort and set
F90 = mpiifort -DILP64 # <---Note here it is "mpiifort", not "mpifort" !! Two i !!
LIB = -mkl=parallel
OPT = -qopenmp -i8 -xHOST -ilp64 -O3
Then compile with
make -f Makefile.mpiifort
Do not use parallel make -j. After successful build, rename the outcoming binary executable:
mv /phi/pkg/smash-2.1.0/bin/smash /phi/pkg/smash-2.1.0/bin/smash.intel64.impi
Cleanup the object files for the next build:
make -f Makefile.mpiifort clean
Compile another version of binary for mic0 using -mmic
cp Makefile.mpiifort Makefile.mpiifort.mic
Edit Makefile.mpiifort.mic and set
F90 = mpiifort -DILP64
LIB = -mkl=parallel
OPT = -qopenmp -i8 -xHOST -ilp64 -O3 -mmic
Then compile with
make -f Makefile.mpiifort.mic
mv /phi/pkg/smash-2.1.0/bin/smash /phi/pkg/smash-2.1.0/bin/smash.mic.impi
Now we have binaries for both architectures under /phi/pkg/smash-2.1.0/bin
ls -al /phi/pkg/smash-2.1.0/bin/smash*.impi
-rwxr-xr-x 1 jsyu ccu 5469540 Jan 27 02:35 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi
-rwxr-xr-x 1 jsyu ccu 7612438 Jan 28 02:46 /phi/pkg/smash-2.1.0/bin/smash.mic.impi
Running test molecule (taxol, C47H51NO14) from the example file
/phi/pkg/smash-2.1.0/example/large-memory.inp but change to DFT instead of MP2:
cp /phi/pkg/smash-2.1.0/example/large-memory.inp large-memory-b3.inp
Edit the input file large-memory-b3.inp and change the first line method=MP2 into method=B3LYP and reduce memory=7GB
OMP_NUM_THREADS=20 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.openmp &
After finish, grep the timing data
grep -A 1 "Step CPU :" large-memory-b3.q183.openmp
The third step computes B3LYP/STO-3G energy from huckel guess; its timing is highlighted:
Step CPU : 8.3, Total CPU : 8.3 of Master node
Step Wall : 0.2, Total Wall : 0.2 at Sat Jan 28 14:30:30 2017
--
Step CPU : 354.0, Total CPU : 362.3 of Master node
Step Wall : 9.1, Total Wall : 9.3 at Sat Jan 28 14:30:39 2017
--
Step CPU : 3286.7, Total CPU : 3649.0 of Master node
Step Wall : 84.3, Total Wall : 93.6 at Sat Jan 28 14:32:03 2017
--
Step CPU : 2.4, Total CPU : 3651.5 of Master node
Step Wall : 0.1, Total Wall : 93.6 at Sat Jan 28 14:32:03 2017
OMP_NUM_THREADS=20 /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.openmp.60 &
Timing data of 60 OMP threads in large-memory-b3.mic0.openmp.60
Step CPU : 66.3, Total CPU : 66.3 of Master node
Step Wall : 1.2, Total Wall : 1.2 at Sat Jan 28 14:12:06 2017
--
Step CPU : 1759.9, Total CPU : 1826.1 of Master node
Step Wall : 29.3, Total Wall : 30.5 at Sat Jan 28 14:12:35 2017
--
Step CPU : 15690.6, Total CPU : 17516.7 of Master node
Step Wall : 263.2, Total Wall : 293.7 at Sat Jan 28 14:16:59 2017
--
Step CPU : 6.7, Total CPU : 17523.4 of Master node
Step Wall : 0.1, Total Wall : 293.8 at Sat Jan 28 14:16:59 2017
@q183
Using impi parallel on host (1 process x 20 threads):
OMP_NUM_THREADS=20 mpiexec.hydra -np 1 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.1p20t &
Timing data of 20 MPI threads in large-memory-b3.q183.impi.1p20t
Step CPU : 2.4, Total CPU : 2.4 of Master node
Step Wall : 0.1, Total Wall : 0.1 at Sat Jan 28 19:31:21 2017
--
Step CPU : 224.1, Total CPU : 226.4 of Master node
Step Wall : 11.2, Total Wall : 11.3 at Sat Jan 28 19:31:33 2017
--
Step CPU : 1947.4, Total CPU : 2173.8 of Master node
Step Wall : 97.6, Total Wall : 108.9 at Sat Jan 28 19:33:10 2017
--
Step CPU : 0.2, Total CPU : 2174.0 of Master node
Step Wall : 0.0, Total Wall : 108.9 at Sat Jan 28 19:33:10 2017
Using impi parallel on host (1 process x 40 threads):
mpiexec.hydra -np 1 -ppn 1 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.1p1t &
Timing data of 40 MPI threads in large-memory-b3.q183.impi.1p1t
Step CPU : 7.8, Total CPU : 7.8 of Master node
Step Wall : 0.2, Total Wall : 0.2 at Sat Jan 28 15:25:09 2017
--
Step CPU : 355.3, Total CPU : 363.1 of Master node
Step Wall : 9.1, Total Wall : 9.3 at Sat Jan 28 15:25:18 2017
--
Step CPU : 3241.8, Total CPU : 3604.9 of Master node
Step Wall : 85.4, Total Wall : 94.8 at Sat Jan 28 15:26:43 2017
--
Step CPU : 1.3, Total CPU : 3606.2 of Master node
Step Wall : 0.0, Total Wall : 94.8 at Sat Jan 28 15:26:43 2017
Using impi parallel on host (20 process x 2 threads):
OMP_NUM_THREADS=2 mpiexec.hydra -np 20 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.20p2t &
Timing data of 40 MPI threads in large-memory-b3.q183.impi.20p2t
Step CPU : 0.5, Total CPU : 0.5 of Master node
Step Wall : 0.3, Total Wall : 0.3 at Sat Jan 28 19:49:06 2017
--
Step CPU : 18.8, Total CPU : 19.3 of Master node
Step Wall : 9.7, Total Wall : 9.9 at Sat Jan 28 19:49:16 2017
--
Step CPU : 167.2, Total CPU : 186.6 of Master node
Step Wall : 83.8, Total Wall : 93.7 at Sat Jan 28 19:50:40 2017
--
Step CPU : 0.0, Total CPU : 186.6 of Master node
Step Wall : 0.0, Total Wall : 93.7 at Sat Jan 28 19:50:40 2017
@mic
Using impi parallel on mic0 (1 process x 244 threads):
Must export I_MPI_MIC=1 or export I_MPI_MIC=enable before running !!
Submit the job to mic from host, not from mic!
mpiexec.hydra -np 1 -host mic0 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.impi.1 &
Timing data of 1x244 MPI threads in large-memory-b3.mic0.impi.1
Step CPU : 523.1, Total CPU : 523.1 of Master node
Step Wall : 2.5, Total Wall : 2.5 at Sat Jan 28 14:38:16 2017
--
Step CPU : 4845.5, Total CPU : 5368.6 of Master node
Step Wall : 20.3, Total Wall : 22.8 at Sat Jan 28 14:38:37 2017
--
Step CPU : 34261.4, Total CPU : 39630.0 of Master node
Step Wall : 141.5, Total Wall : 164.3 at Sat Jan 28 14:40:58 2017
--
Step CPU : 49.1, Total CPU : 39679.1 of Master node
Step Wall : 0.2, Total Wall : 164.6 at Sat Jan 28 14:40:58 2017
==> 34261.4÷141.5=241.1x
Using impi parallel on mic0 (61 process x 4 threads):
mpiexec.hydra -np 61 -host mic0 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.impi.61x4 &
Timing data of 61x4 MPI threads in large-memory-b3.mic0.impi.61x4
Step CPU : 8.0, Total CPU : 8.0 of Master node
Step Wall : 2.9, Total Wall : 2.9 at Sat Jan 28 16:26:52 2017
--
Step CPU : 72.3, Total CPU : 80.4 of Master node
Step Wall : 18.7, Total Wall : 21.6 at Sat Jan 28 16:27:11 2017
--
Step CPU : 555.5, Total CPU : 635.9 of Master node
Step Wall : 140.5, Total Wall : 162.1 at Sat Jan 28 16:29:31 2017
--
Step CPU : 0.7, Total CPU : 636.5 of Master node
Step Wall : 0.2, Total Wall : 162.3 at Sat Jan 28 16:29:32 2017
Using impi parallel on mic0 (244 process x 1 threads):
mpiexec.hydra -np 244 -host mic0 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.impi.244x1 &
Died.... Probably out of memory ???
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= PID 10328 RUNNING AT mic0
= EXIT CODE: 9
= CLEANING UP REMAINING PROCESSES
= YOU CAN IGNORE THE BELOW CLEANUP MESSAGES
===================================================================================
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= PID 10328 RUNNING AT mic0
= EXIT CODE: 9
= CLEANING UP REMAINING PROCESSES
= YOU CAN IGNORE THE BELOW CLEANUP MESSAGES
===================================================================================
Intel(R) MPI Library troubleshooting guide:
https://software.intel.com/node/561764
===================================================================================
mic1
Then run with
I_MPI_FABRICS=shm:tcp mpiexec.hydra -machinefile hostfile -ppn 244 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0+1.impi.2x1x244 &
Timing data of 2x1x244 MPI threads in large-memory-b3.mic0.impi.2x1x244
Step CPU : 547.2, Total CPU : 547.2 of Master node
Step Wall : 2.6, Total Wall : 2.6 at Sat Jan 28 17:13:18 2017
--
Step CPU : 3335.4, Total CPU : 3882.6 of Master node
Step Wall : 14.7, Total Wall : 17.3 at Sat Jan 28 17:13:32 2017
--
Step CPU : 19142.3, Total CPU : 23024.8 of Master node
Step Wall : 79.5, Total Wall : 96.7 at Sat Jan 28 17:14:52 2017
--
Step CPU : 49.9, Total CPU : 23074.8 of Master node
Step Wall : 0.2, Total Wall : 97.0 at Sat Jan 28 17:14:52 2017
==> 19142.3÷79.5=240.8x
Hybrid mode @ CPU+Phi, CPU(1 process x 40 threads) + Phi 2x(1 process x 244 threads):
I_MPI_MIC=enable I_MPI_FABRICS=shm:tcp mpiexec.hydra -np 1 -host q183 -ppn 40 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi : -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH -env OMP_NUM_THREADS 244 -np 1 -host mic0 /phi/pkg/smash-2.1.0/bin/smash.mic.impi : -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH -env OMP_NUM_THREADS 244 -np 1 -host mic1 /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.q183+mic01.impi.488+40 &
Timing data of 1x40+2x1x244 MPI threads in large-memory-b3.q183+mic01.impi.488+40
Step CPU : 20.7, Total CPU : 20.7 of Master node
Step Wall : 1.7, Total Wall : 1.7 at Sun Jan 29 00:24:45 2017
--
Step CPU : 233.1, Total CPU : 253.8 of Master node
Step Wall : 11.2, Total Wall : 12.9 at Sun Jan 29 00:24:56 2017
--
Step CPU : 1430.7, Total CPU : 1684.5 of Master node
Step Wall : 58.6, Total Wall : 71.4 at Sun Jan 29 00:25:55 2017
--
Step CPU : 3.0, Total CPU : 1687.5 of Master node
Step Wall : 0.1, Total Wall : 71.5 at Sun Jan 29 00:25:55 2017
Concluding Remark (temporary)
Maybe ~80 seconds is the upper limit of parallelization to this size of problem ???
Or the performance of two Intel Phi cards is roughly equal to two E5-2670v2@2.3GHz ???
To be continued.....
1. Try mpitune and Intel Trace Analyzer (ref 2,3)
2. Play with KMP_AFFINITY= (ref 4)
3. Any available options in addition to I_MPI_FABRICS=shm:tcp
================================== NOTES ========================================
Debug log:
1. Edit /etc/hosts and added
172.31.1.254 phi
This solves error message similar to:
HYDU_getfullhostname (../../utils/others/others.c:146): getaddrinfo error (hostname: phi, error: Name or service not known)
2. Add OMP_STACKSIZE=1G if problems occur before SCF iterations. This applies to both OpenMP and MPI runs.
References:
Environment
Intel Compiler Version 17.0.1.132 Build 20161005Python v2.6.6
. /opt/intel/compilers_and_libraries_2017/linux/bin/compilervars.sh intel64
. /opt/intel/impi/2017.1.132/bin64/mpivars.sh intel64
echo $MKLROOT
/opt/intel/compilers_and_libraries_2017.1.132/linux/mkl
echo $MIC_LD_LIBRARY_PATH
/opt/intel/compilers_and_libraries_2017.1.132/linux/mpi/mic/lib:/opt/intel/compilers_and_libraries_2017.1.132/linux/compiler/lib/mic:/opt/intel/compilers_and_libraries_2017.1.132/linux/ipp/lib/mic:/opt/intel/mic/coi/device-linux-release/lib:/opt/intel/mic/myo/lib:/opt/intel/compilers_and_libraries_2017.1.132/linux/compiler/lib/intel64_lin_mic:/opt/intel/compilers_and_libraries_2017.1.132/linux/mkl/lib/intel64_lin_mic:/opt/intel/compilers_and_libraries_2017.1.132/linux/tbb/lib/mic
Compilation
Compilation with Intel compiler with both OpenMP and Intel MPI (impi) interfaces can make one single binary run in parallel via the control using OMP_NUM_THREADS and mpirunCompile on host with for the intel64 architecture
cd /phi/pkg/smash-2.1.0
cp Makefile Makefile.mpiifort
Edit Makefile.mpiifort and set
F90 = mpiifort -DILP64 # <---Note here it is "mpiifort", not "mpifort" !! Two i !!
LIB = -mkl=parallel
OPT = -qopenmp -i8 -xHOST -ilp64 -O3
Then compile with
make -f Makefile.mpiifort
Do not use parallel make -j. After successful build, rename the outcoming binary executable:
mv /phi/pkg/smash-2.1.0/bin/smash /phi/pkg/smash-2.1.0/bin/smash.intel64.impi
Cleanup the object files for the next build:
make -f Makefile.mpiifort clean
Compile another version of binary for mic0 using -mmic
cp Makefile.mpiifort Makefile.mpiifort.mic
Edit Makefile.mpiifort.mic and set
F90 = mpiifort -DILP64
LIB = -mkl=parallel
OPT = -qopenmp -i8 -xHOST -ilp64 -O3 -mmic
Then compile with
make -f Makefile.mpiifort.mic
mv /phi/pkg/smash-2.1.0/bin/smash /phi/pkg/smash-2.1.0/bin/smash.mic.impi
Now we have binaries for both architectures under /phi/pkg/smash-2.1.0/bin
ls -al /phi/pkg/smash-2.1.0/bin/smash*.impi
-rwxr-xr-x 1 jsyu ccu 5469540 Jan 27 02:35 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi
-rwxr-xr-x 1 jsyu ccu 7612438 Jan 28 02:46 /phi/pkg/smash-2.1.0/bin/smash.mic.impi
Running test molecule (taxol, C47H51NO14) from the example file
/phi/pkg/smash-2.1.0/example/large-memory.inp but change to DFT instead of MP2:
cp /phi/pkg/smash-2.1.0/example/large-memory.inp large-memory-b3.inp
Edit the input file large-memory-b3.inp and change the first line method=MP2 into method=B3LYP and reduce memory=7GB
OpenMP Run
Using OpenMP parallel on host (using 20 threads):OMP_NUM_THREADS=20 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.openmp &
After finish, grep the timing data
grep -A 1 "Step CPU :" large-memory-b3.q183.openmp
The third step computes B3LYP/STO-3G energy from huckel guess; its timing is highlighted:
Step CPU : 8.3, Total CPU : 8.3 of Master node
Step Wall : 0.2, Total Wall : 0.2 at Sat Jan 28 14:30:30 2017
--
Step CPU : 354.0, Total CPU : 362.3 of Master node
Step Wall : 9.1, Total Wall : 9.3 at Sat Jan 28 14:30:39 2017
--
Step CPU : 3286.7, Total CPU : 3649.0 of Master node
Step Wall : 84.3, Total Wall : 93.6 at Sat Jan 28 14:32:03 2017
--
Step CPU : 2.4, Total CPU : 3651.5 of Master node
Step Wall : 0.1, Total Wall : 93.6 at Sat Jan 28 14:32:03 2017
Using OpenMP parallel on mic0 (using 60 threads), native mode:
Login to mic0, and add environments
export \ LD_LIBRARY_PATH="/opt/intel/compilers_and_libraries_2017.1.132/linux/mkl/lib/mic:/opt/intel/compilers_and_libraries_2017.1.132/linux/compiler/lib/mic"
ulimit -s unlimited
OMP_NUM_THREADS=20 /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.openmp.60 &
Timing data of 60 OMP threads in large-memory-b3.mic0.openmp.60
Step CPU : 66.3, Total CPU : 66.3 of Master node
Step Wall : 1.2, Total Wall : 1.2 at Sat Jan 28 14:12:06 2017
--
Step CPU : 1759.9, Total CPU : 1826.1 of Master node
Step Wall : 29.3, Total Wall : 30.5 at Sat Jan 28 14:12:35 2017
--
Step CPU : 15690.6, Total CPU : 17516.7 of Master node
Step Wall : 263.2, Total Wall : 293.7 at Sat Jan 28 14:16:59 2017
--
Step CPU : 6.7, Total CPU : 17523.4 of Master node
Step Wall : 0.1, Total Wall : 293.8 at Sat Jan 28 14:16:59 2017
Timing data of 240 OMP threads in large-memory-b3.mic0.openmp.240
Step CPU : 488.2, Total CPU : 488.2 of Master node
Step Wall : 2.3, Total Wall : 2.3 at Sat Jan 28 04:37:43 2017
--
Step CPU : 4645.1, Total CPU : 5133.3 of Master node
Step Wall : 19.6, Total Wall : 21.8 at Sat Jan 28 04:38:03 2017
--
Step CPU : 43990.2, Total CPU : 49123.5 of Master node
Step Wall : 184.6, Total Wall : 206.4 at Sat Jan 28 04:41:07 2017
--
Step CPU : 55.5, Total CPU : 49179.0 of Master node
Step Wall : 0.2, Total Wall : 206.6 at Sat Jan 28 04:41:08 2017
Step CPU : 488.2, Total CPU : 488.2 of Master node
Step Wall : 2.3, Total Wall : 2.3 at Sat Jan 28 04:37:43 2017
--
Step CPU : 4645.1, Total CPU : 5133.3 of Master node
Step Wall : 19.6, Total Wall : 21.8 at Sat Jan 28 04:38:03 2017
--
Step CPU : 43990.2, Total CPU : 49123.5 of Master node
Step Wall : 184.6, Total Wall : 206.4 at Sat Jan 28 04:41:07 2017
--
Step CPU : 55.5, Total CPU : 49179.0 of Master node
Step Wall : 0.2, Total Wall : 206.6 at Sat Jan 28 04:41:08 2017
Intel MPI Run (impi)
Using impi parallel on host (1 process x 20 threads):
OMP_NUM_THREADS=20 mpiexec.hydra -np 1 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.1p20t &
Timing data of 20 MPI threads in large-memory-b3.q183.impi.1p20t
Step CPU : 2.4, Total CPU : 2.4 of Master node
Step Wall : 0.1, Total Wall : 0.1 at Sat Jan 28 19:31:21 2017
--
Step CPU : 224.1, Total CPU : 226.4 of Master node
Step Wall : 11.2, Total Wall : 11.3 at Sat Jan 28 19:31:33 2017
--
Step CPU : 1947.4, Total CPU : 2173.8 of Master node
Step Wall : 97.6, Total Wall : 108.9 at Sat Jan 28 19:33:10 2017
--
Step CPU : 0.2, Total CPU : 2174.0 of Master node
Step Wall : 0.0, Total Wall : 108.9 at Sat Jan 28 19:33:10 2017
mpiexec.hydra -np 1 -ppn 1 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.1p1t &
Timing data of 40 MPI threads in large-memory-b3.q183.impi.1p1t
Step CPU : 7.8, Total CPU : 7.8 of Master node
Step Wall : 0.2, Total Wall : 0.2 at Sat Jan 28 15:25:09 2017
--
Step CPU : 355.3, Total CPU : 363.1 of Master node
Step Wall : 9.1, Total Wall : 9.3 at Sat Jan 28 15:25:18 2017
--
Step CPU : 3241.8, Total CPU : 3604.9 of Master node
Step Wall : 85.4, Total Wall : 94.8 at Sat Jan 28 15:26:43 2017
--
Step CPU : 1.3, Total CPU : 3606.2 of Master node
Step Wall : 0.0, Total Wall : 94.8 at Sat Jan 28 15:26:43 2017
Using impi parallel on host (2 process x 20 threads):
OMP_NUM_THREADS=20 mpiexec.hydra -np 2 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.2p20t &
Timing data of 40 MPI threads in large-memory-b3.q183.impi.2p20t
Step CPU : 4.0, Total CPU : 4.0 of Master node
Step Wall : 0.2, Total Wall : 0.2 at Sat Jan 28 19:36:12 2017
--
Step CPU : 177.0, Total CPU : 181.0 of Master node
Step Wall : 8.9, Total Wall : 9.1 at Sat Jan 28 19:36:21 2017
--
Step CPU : 1643.5, Total CPU : 1824.6 of Master node
Step Wall : 82.2, Total Wall : 91.4 at Sat Jan 28 19:37:43 2017
--
Step CPU : 1.2, Total CPU : 1825.7 of Master node
Step Wall : 0.1, Total Wall : 91.4 at Sat Jan 28 19:37:43 2017
OMP_NUM_THREADS=20 mpiexec.hydra -np 2 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.2p20t &
Timing data of 40 MPI threads in large-memory-b3.q183.impi.2p20t
Step CPU : 4.0, Total CPU : 4.0 of Master node
Step Wall : 0.2, Total Wall : 0.2 at Sat Jan 28 19:36:12 2017
--
Step CPU : 177.0, Total CPU : 181.0 of Master node
Step Wall : 8.9, Total Wall : 9.1 at Sat Jan 28 19:36:21 2017
--
Step CPU : 1643.5, Total CPU : 1824.6 of Master node
Step Wall : 82.2, Total Wall : 91.4 at Sat Jan 28 19:37:43 2017
--
Step CPU : 1.2, Total CPU : 1825.7 of Master node
Step Wall : 0.1, Total Wall : 91.4 at Sat Jan 28 19:37:43 2017
OMP_NUM_THREADS=2 mpiexec.hydra -np 20 -host q183 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi < large-memory-b3.inp > large-memory-b3.q183.impi.20p2t &
Timing data of 40 MPI threads in large-memory-b3.q183.impi.20p2t
Step CPU : 0.5, Total CPU : 0.5 of Master node
Step Wall : 0.3, Total Wall : 0.3 at Sat Jan 28 19:49:06 2017
--
Step CPU : 18.8, Total CPU : 19.3 of Master node
Step Wall : 9.7, Total Wall : 9.9 at Sat Jan 28 19:49:16 2017
--
Step CPU : 167.2, Total CPU : 186.6 of Master node
Step Wall : 83.8, Total Wall : 93.7 at Sat Jan 28 19:50:40 2017
--
Step CPU : 0.0, Total CPU : 186.6 of Master node
Step Wall : 0.0, Total Wall : 93.7 at Sat Jan 28 19:50:40 2017
Using impi parallel on mic0 (1 process x 244 threads):
Must export I_MPI_MIC=1 or export I_MPI_MIC=enable before running !!
Submit the job to mic from host, not from mic!
mpiexec.hydra -np 1 -host mic0 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.impi.1 &
Timing data of 1x244 MPI threads in large-memory-b3.mic0.impi.1
Step CPU : 523.1, Total CPU : 523.1 of Master node
Step Wall : 2.5, Total Wall : 2.5 at Sat Jan 28 14:38:16 2017
--
Step CPU : 4845.5, Total CPU : 5368.6 of Master node
Step Wall : 20.3, Total Wall : 22.8 at Sat Jan 28 14:38:37 2017
--
Step CPU : 34261.4, Total CPU : 39630.0 of Master node
Step Wall : 141.5, Total Wall : 164.3 at Sat Jan 28 14:40:58 2017
--
Step CPU : 49.1, Total CPU : 39679.1 of Master node
Step Wall : 0.2, Total Wall : 164.6 at Sat Jan 28 14:40:58 2017
==> 34261.4÷141.5=241.1x
Using impi parallel on mic0 (61 process x 4 threads):
mpiexec.hydra -np 61 -host mic0 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.impi.61x4 &
Timing data of 61x4 MPI threads in large-memory-b3.mic0.impi.61x4
Step CPU : 8.0, Total CPU : 8.0 of Master node
Step Wall : 2.9, Total Wall : 2.9 at Sat Jan 28 16:26:52 2017
--
Step CPU : 72.3, Total CPU : 80.4 of Master node
Step Wall : 18.7, Total Wall : 21.6 at Sat Jan 28 16:27:11 2017
--
Step CPU : 555.5, Total CPU : 635.9 of Master node
Step Wall : 140.5, Total Wall : 162.1 at Sat Jan 28 16:29:31 2017
--
Step CPU : 0.7, Total CPU : 636.5 of Master node
Step Wall : 0.2, Total Wall : 162.3 at Sat Jan 28 16:29:32 2017
Using impi parallel on mic0 (244 process x 1 threads):
mpiexec.hydra -np 244 -host mic0 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0.impi.244x1 &
Died.... Probably out of memory ???
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= PID 10328 RUNNING AT mic0
= EXIT CODE: 9
= CLEANING UP REMAINING PROCESSES
= YOU CAN IGNORE THE BELOW CLEANUP MESSAGES
===================================================================================
===================================================================================
= BAD TERMINATION OF ONE OF YOUR APPLICATION PROCESSES
= PID 10328 RUNNING AT mic0
= EXIT CODE: 9
= CLEANING UP REMAINING PROCESSES
= YOU CAN IGNORE THE BELOW CLEANUP MESSAGES
===================================================================================
Intel(R) MPI Library troubleshooting guide:
https://software.intel.com/node/561764
===================================================================================
Using impi parallel on mic0+mic1, 2x(1 process x 244 threads) :
Create ./hostfile containing two lines,
mic0mic1
Then run with
I_MPI_FABRICS=shm:tcp mpiexec.hydra -machinefile hostfile -ppn 244 -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.mic0+1.impi.2x1x244 &
Timing data of 2x1x244 MPI threads in large-memory-b3.mic0.impi.2x1x244
Step CPU : 547.2, Total CPU : 547.2 of Master node
Step Wall : 2.6, Total Wall : 2.6 at Sat Jan 28 17:13:18 2017
--
Step CPU : 3335.4, Total CPU : 3882.6 of Master node
Step Wall : 14.7, Total Wall : 17.3 at Sat Jan 28 17:13:32 2017
--
Step CPU : 19142.3, Total CPU : 23024.8 of Master node
Step Wall : 79.5, Total Wall : 96.7 at Sat Jan 28 17:14:52 2017
--
Step CPU : 49.9, Total CPU : 23074.8 of Master node
Step Wall : 0.2, Total Wall : 97.0 at Sat Jan 28 17:14:52 2017
==> 19142.3÷79.5=240.8x
Hybrid mode @ CPU+Phi, CPU(1 process x 40 threads) + Phi 2x(1 process x 244 threads):
I_MPI_MIC=enable I_MPI_FABRICS=shm:tcp mpiexec.hydra -np 1 -host q183 -ppn 40 /phi/pkg/smash-2.1.0/bin/smash.intel64.impi : -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH -env OMP_NUM_THREADS 244 -np 1 -host mic0 /phi/pkg/smash-2.1.0/bin/smash.mic.impi : -env LD_LIBRARY_PATH $MIC_LD_LIBRARY_PATH -env OMP_NUM_THREADS 244 -np 1 -host mic1 /phi/pkg/smash-2.1.0/bin/smash.mic.impi < large-memory-b3.inp > large-memory-b3.q183+mic01.impi.488+40 &
Timing data of 1x40+2x1x244 MPI threads in large-memory-b3.q183+mic01.impi.488+40
Step CPU : 20.7, Total CPU : 20.7 of Master node
Step Wall : 1.7, Total Wall : 1.7 at Sun Jan 29 00:24:45 2017
--
Step CPU : 233.1, Total CPU : 253.8 of Master node
Step Wall : 11.2, Total Wall : 12.9 at Sun Jan 29 00:24:56 2017
--
Step CPU : 1430.7, Total CPU : 1684.5 of Master node
Step Wall : 58.6, Total Wall : 71.4 at Sun Jan 29 00:25:55 2017
--
Step CPU : 3.0, Total CPU : 1687.5 of Master node
Step Wall : 0.1, Total Wall : 71.5 at Sun Jan 29 00:25:55 2017
Concluding Remark (temporary)
Maybe ~80 seconds is the upper limit of parallelization to this size of problem ???
Or the performance of two Intel Phi cards is roughly equal to two E5-2670v2@2.3GHz ???
To be continued.....
1. Try mpitune and Intel Trace Analyzer (ref 2,3)
2. Play with KMP_AFFINITY= (ref 4)
3. Any available options in addition to I_MPI_FABRICS=shm:tcp
================================== NOTES ========================================
Debug log:
1. Edit /etc/hosts and added
172.31.1.254 phi
This solves error message similar to:
HYDU_getfullhostname (../../utils/others/others.c:146): getaddrinfo error (hostname: phi, error: Name or service not known)
2. Add OMP_STACKSIZE=1G if problems occur before SCF iterations. This applies to both OpenMP and MPI runs.
References:
- https://software.intel.com/en-us/forums/intel-many-integrated-core/topic/542161
- https://software.intel.com/en-us/node/528811
- http://slidegur.com/doc/76099/software-and-services-group
- https://software.intel.com/en-us/node/522691
Sunday, November 20, 2005
Software RAID5 archived ~37 MB/sec resync speed with two pieces of 3ware 9550SX-8LP
# mdadm -Cv /dev/md7 -l5 -n15 -x1 -c128 /dev/sd[c-r]1
Personalities : [raid1] [raid5]
md7 : active raid5 sdq1[15] sdr1[16](S) sdp1[13] sdo1[12] sdn1[11] sdm1[10] sdl1[9] sdk1[8] sdj1[7] sdi1[6] sdh1[5] sdg1[4] sdf1[3] sde1[2] sdd1[1] sdc1[0]
4102468608 blocks level 5, 128k chunk, algorithm 2 [15/14] [UUUUUUUUUUUUUU_]
[>....................] recovery = 0.6% (1908296/293033472) finish=131.1min speed=36998K/sec
3ware 9000 Storage Controller device driver for Linux v2.26.04.006.
Firmware FE9X 3.01.01.028, BIOS BE9X 3.01.00.024.
# mdadm -Cv /dev/md7 -l5 -n15 -x1 -c128 /dev/sd[c-r]1
Personalities : [raid1] [raid5]
md7 : active raid5 sdq1[15] sdr1[16](S) sdp1[13] sdo1[12] sdn1[11] sdm1[10] sdl1[9] sdk1[8] sdj1[7] sdi1[6] sdh1[5] sdg1[4] sdf1[3] sde1[2] sdd1[1] sdc1[0]
4102468608 blocks level 5, 128k chunk, algorithm 2 [15/14] [UUUUUUUUUUUUUU_]
[>....................] recovery = 0.6% (1908296/293033472) finish=131.1min speed=36998K/sec
3ware 9000 Storage Controller device driver for Linux v2.26.04.006.
Firmware FE9X 3.01.01.028, BIOS BE9X 3.01.00.024.
Wednesday, November 16, 2005
Setting 'max_queue' options for sx8.ko increases RAID5 recovery speed to ~23 MB/sec
Unload sx8 module. Add
options sx8 max_queue=24
to /etc/modules.conf and reload sx8. Now the recovery speed with a single adaptor and 8 drives is increased to 23000K/sec.
The effect of max_queue=32 has not much difference but in the comment of sx8.c version 1.0 it is claimed that problems seem to occur when the value exceeds ~30.
Thanks to Jeff Garzik's ultra-prompt reply in five minutes.
Unload sx8 module. Add
options sx8 max_queue=24
to /etc/modules.conf and reload sx8. Now the recovery speed with a single adaptor and 8 drives is increased to 23000K/sec.
The effect of max_queue=32 has not much difference but in the comment of sx8.c version 1.0 it is claimed that problems seem to occur when the value exceeds ~30.
Thanks to Jeff Garzik's ultra-prompt reply in five minutes.
Monday, November 14, 2005
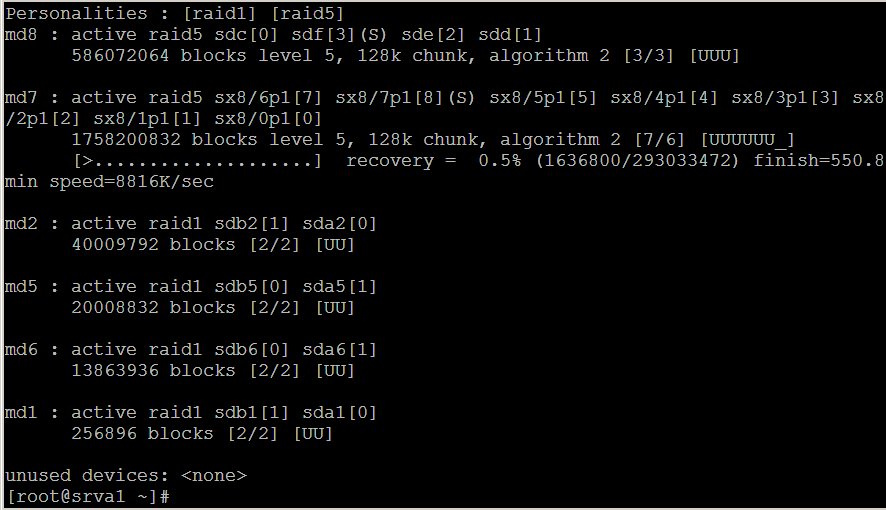
Friday, October 28, 2005
A fileserver of 4.2 TB in size drowned Zippy 650W power supply
The specification of fileserver:
Changing to one of the following is under consideration:
The specification of fileserver:
- Supermicro PDSME Motherboard
- Intel Pentium-4 820 Dual Core / Dual 1MB L2 cache / 800 MHz FSB
- 4 x 1GB DDR2-533 (Transcend TS128MLQ64V5J)
- 2 x Promise SATAII-150SX8 Controller (8 SATA ports each)
- 16 x 3.5" Seagate 7200rpm 300GB SATA HDD with 8MB cache (ST3300831AS)
- 2 x 2.5" Seagate 5400rpm 80GB SATA HDD with 8MB cache (ST98823AS)
- 1 x Intel Pro/1000MT Dual Port Gigabit Controller (PWLA8492MT)
- 1 x Intel Pro/100M Single Port FastEthernet Controller (PILA8460M)
Changing to one of the following is under consideration:
- P2M6600P(600W) +12V=42A +5V=35A
- P2M6601P(600W) +12V=48A +5V=30A
- H3M6600P(600W) +12V=48A +5V=30A
Wednesday, October 26, 2005
NWChem 4.7 out of memory/swap problem with GOTO 1.0 in EM64T
A simple DFT task of 480 basis functions failed due to "out of memory". All of the system memory and swap space were occupied (3GB RAM, 15GB swap and counting......) no matter what number had been set to "memory total" keyword. Switching linking BLAS library from libgoto_prescott64p-r1.00.so to MKL 7.2c solved the problem, and this task actually only require ~60MB of RAM.
A simple DFT task of 480 basis functions failed due to "out of memory". All of the system memory and swap space were occupied (3GB RAM, 15GB swap and counting......) no matter what number had been set to "memory total" keyword. Switching linking BLAS library from libgoto_prescott64p-r1.00.so to MKL 7.2c solved the problem, and this task actually only require ~60MB of RAM.
Tuesday, October 25, 2005
Subscribe to:
Posts (Atom)